
The world of cloud is a world of big numbers. Millions of devices. Billions of files. Trillions of events. At some point, all these big numbers need to be stored somewhere.
Object storage is a form of cloud storage designed to keep huge amounts of data, using metadata for organization. Data is split into a pool of objects, and metadata allows you to sort and search your objects in as many ways as you need.
This is the final article in a three-part series about common types of cloud storage, how each technology works, what they’re good for, and how to use them. Block storage is ideal for high-performance applications. File storage is great for sharing files among lots of clients. We’ll finish by exploring object storage and how it gives us the scale we expect from the cloud.
How does object storage work?
An object is a file plus metadata, and an object store is a collection of objects. Each object has a unique ID, and you use that ID to find your objects within the store.
Although object IDs sometimes look like file paths, object stores are fundamentally different from file storage. Object stores keep data in a way that gives them much more room to scale.
Block storage and file storage both struggle to scale because they have a single lookup table, which can only grow so far. Object stores avoid this limitation by splitting themselves into multiple layers: a router and storage nodes.
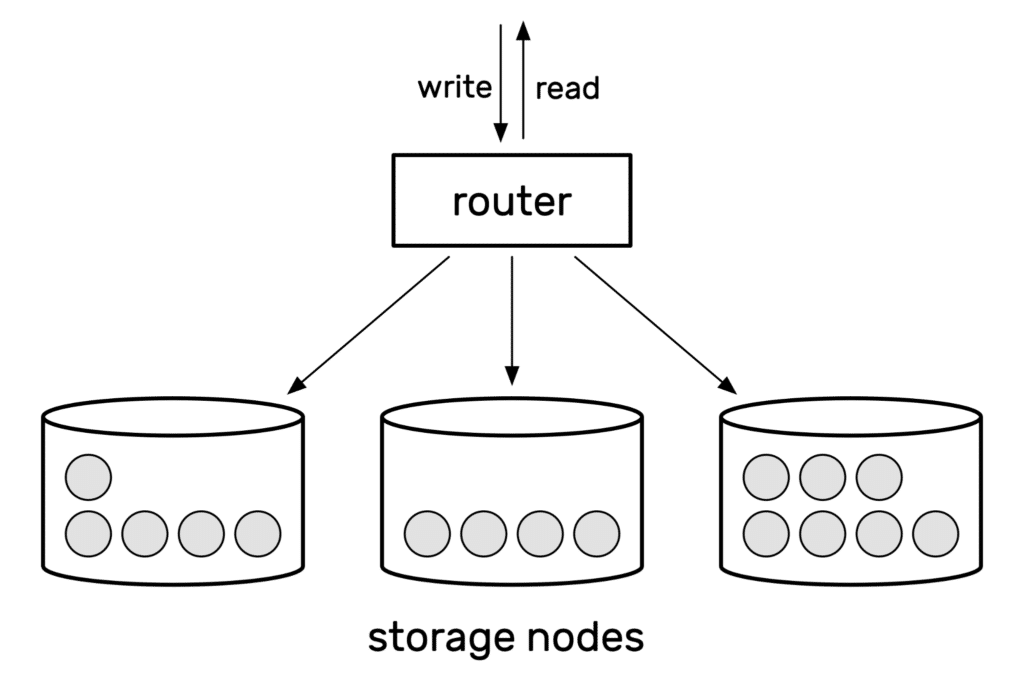
Individual objects are sharded across a series of storage nodes. You don’t interact with these nodes directly; instead, you interact with the router. When you try to read or write an object, you make an HTTP request to the router, and it routes your request to the storage node that owns the relevant object.
Each storage node uses a local file system (probably block storage) to manage its objects. Objects are split across multiple nodes to ensure that no single node gets too big, to prevent node-level scaling issues. If all the existing nodes are full, the object store can add new nodes to spread the load.
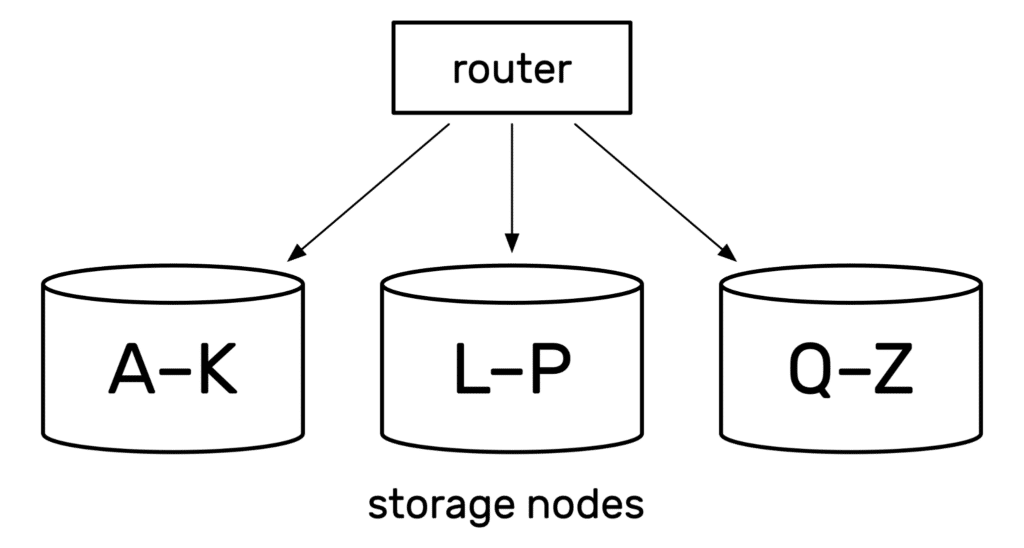
The router has to know which object is on which node. It keeps a list of rules for assigning object IDs to nodes, rather than a complete list of rules. These rules can be comparatively small and simple, even with thousands of nodes.
For example, suppose the object IDs are alphabetic strings. It could put all the IDs beginning A-K on one node, the IDs beginning L-P on another node, and the IDs beginning Q-Z on the third node. These rules make it easy to work out which node owns a particular object so it can route requests accordingly.
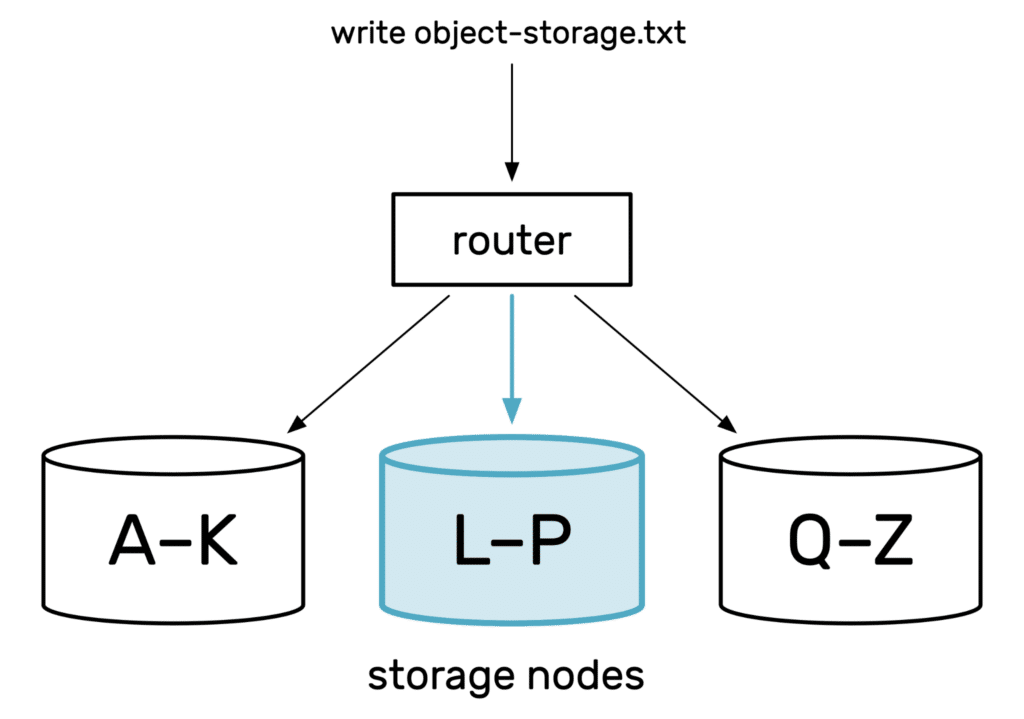
If a request comes in to write an object with the ID object-storage.txt, the router uses the rules to send the request to the second node. If it’s later asked to retrieve the object, it uses the same rules to find out the second node owns the object, and it forwards the retrieval.
Over time, the object store can adjust the number of storage nodes. It can add nodes if there are a lot of new objects or remove them if the data set is shrinking. It can also move objects between nodes so they stay balanced. Ideally, each node should have a similar number of objects.
This separation allows an object store to hold an incredible number of objects. The lookup tables in both the storage nodes and the router stay relatively small, so they remain manageable. And more storage nodes mean more throughput, so performance scales as the store grows.
Object stores embrace two more concepts to manage this scale: versions and metadata.
You can have multiple versions of an object. Individual versions are immutable, so they can’t be replaced. If you write a new object with the same ID, you get a new version of the object. This makes it easy to handle concurrent writes — if two users write to the same ID simultaneously, you get two versions of the object. You don’t have to deal with conflicting writes.
Metadata gives you new ways to search and slice your objects. As well as tracking when an object is created and who owns it, object stores allow you to tag objects with your own custom metadata. This gives you ways to track and index your objects.
For example, you could record whether an object contains sensitive information, who uses the object, or which department should be billed for the cost. In turn, this metadata can be used to determine other properties, like who can access an object, when to replicate it to another geography, or when to delete it.
This flexibility makes it easier to deal with large amounts of data.
What’s object storage good for?
Object storage is designed for scale, and it’s good for large data sets. Where block or file storage cap out at a few terabytes, a single object store can span petabytes and more. You’ll run out of money before you run out of space.
It’s ideal for large data sets that don’t change very often or that have a lot of associated metadata. This includes media like video and images, data lakes, backups, and archives. Object stores often replace tape as the long-term storage medium of choice.
When shouldn’t I use object storage?
The scale of object storage comes at the cost of performance. The separate layers mean there’s more distance between you and your data, so object storage isn’t as fast as block or file storage. You can potentially connect millions of clients to object storage, but each client will get individually less throughput compared to local block storage.
You also can’t edit individual objects, only write new ones. If you’re making frequent, small edits to an object, then object storage is the wrong choice. Don’t try to run a database on object storage!
How do I get object storage?
Object stores have become the dominant form of cloud storage, so they’re offered by many providers.
The most famous object store is almost certainly Amazon S3. That stands for “Simple Storage Service,” although the “simple” is less true today than when it was first launched. Other object stores include Azure Blob, Google’s unimaginatively named Cloud Storage, and Digital Ocean Spaces.
For some providers, you provision a fixed amount of storage and pay a fixed price (although you can change it later). For others, your storage grows or shrinks with your data and you pay for what you use. Either way, you should have plenty of room to scale.
Some providers allow you to store different objects at different storage tiers, and this is really worth considering. If you don’t retrieve your objects that often, you can put them in cheaper storage tiers for big savings.
The price varies by storage tier — $20 to $30 per terabyte per month at its most expensive, going all the way down to $1 a month for the most infrequently accessed storage tiers. This is substantially cheaper than block or file storage. It’s often a pay-for-what-you-use model rather than a fixed amount upfront.
Object storage: Infinitely scalable but at slower speeds
Object storage is designed to scale forever. It can store arbitrary amounts of data and take requests from as many clients as you have. Its custom metadata gives you powerful ways to analyze your data. If you have a large collection of files that change infrequently, object storage is a great choice.
It’s a poor fit if you want maximum performance or you’re making a lot of edits to files. For those workloads, you should consider block or file storage.
There’s no one way to do storage. Some technologies have a clear progression from old to new, but that’s not true here. Block, file, and object storage all have different characteristics and use cases, and they’ll all be with us for years to come.Compare cloud storage types using the other two articles in our series: block storage and file storage.




